 bug小记
bug小记
# bug 小记
# 业务相关
# 空对象获取属性时怕抛空指针异常
空对象获取属性时会报空指针异常,所以在获取对象属性时要做好空对象校验。
代码举例:
// 正例
EnterpriseEntity enterprise = enterpriseService.getById(enterpriseId);
Assert.notNull(enterprise, "企业不存在!!");
Date createTime = enterprise.getCreateTime();
// 反例 - 第二行会报空指针异常
EnterpriseEntity enterprise = enterpriseService.getById(enterpriseId);
Date createTime = enterprise.getCreateTime();
Assert.notNull(enterprise, "企业不存在!!");
2
3
4
5
6
7
8
9
# Post 方法接收单个参数问题
错误的写法
要注意参数的传递方式**(低级错误)**
@PostMapping("/test/list")
public R<ArrayList<TestVO>> getTest(Long id) {
return messageService.getTest(id);
}
2
3
4
正确的写法
- 封装成一个实体类
- 使用
@RequestParam("")注解标识参数
@PostMapping("/test/list")
public R<ArrayList<TestVO>> getTest(@RequestBody IdDTO idDTO) {
return messageService.getTest(idDTO);
}
// 或者
@PostMapping("/test/list")
public R<ArrayList<TestVO>> getTest(@RequestParam("id") Long id) {
return messageService.getTest(id);
}
2
3
4
5
6
7
8
9
10
# 错误:Parse Error: Invalid header value char
背景分析
将压缩包写入响应流时报的错。
错误代码
String zipName = "压缩包.zip";
try {
response.setContentType("application/zip");
response.setHeader("Content-Disposition", "attachment;filename=" + zipName); // 报错
response.getOutputStream().write(zipStream.toByteArray());
} finally {
zipStream.close();
}
2
3
4
5
6
7
8
9
错误原因
- 这个错误通常是由于
zipName中包含了无效的字符导致的。 - 错误发生在设置响应头(response header)时,具体是在设置
Content-Disposition头的值时出错。 - HTTP 头的值应该是有效的 ASCII 字符,并且不能包含特殊字符或非 ASCII 字符。
- 根据错误信息,
zipName中可能包含了一个或多个无效字符,导致无法设置正确的头值。
- 根据错误信息,
解决方法
对 zipName 进行编码,确保其中的特殊字符被正确处理。你可以使用 URLEncoder 对文件名进行编码,如下所示:
String zipName = "压缩包.zip";
zipName = URLEncoder.encode(zipName, "UTF-8"); // 主要添加这行代码
try {
response.setContentType("application/zip");
response.setHeader("Content-Disposition", "attachment;filename=" + zipName);
response.getOutputStream().write(zipStream.toByteArray());
} finally {
zipStream.close();
}
2
3
4
5
6
7
8
9
10
# jdk 相关
# 报错 jar 不是内部或外部命令,也不是可运行的程序
背景分析
- 指令:
java -version,能正常使用 - 指令:
javac,不能正常使用 - 指令:
jar,不能正常使用
原因分析
问题就就出在这个 Path 上,划重点 ,Path 路径中的【%JAVA_HOME%\bin】和【%JAVA_HOME%\jre\bin】不能放在同一个行里
参考:win10报错jar不是内部或外部命令,也不是可运行的程序_jar' 不是内部或外部命令,也不是可运行的程序 或批处理文件。-CSDN博客 (opens new window)
# 消息队列相关
# 消费者组 ID 问题
便于排查问题
在使用消息队列时,定义有效的消费者组 ID有利于查看数据运行的走向,便于排查问题。
为什么要使用消费者组 ID,有什么好处?不使用有什么不好?(下面以使用 Kafka 为例)
消费者组 ID 是 Apache Kafka 中用于管理消费者的重要概念,它具有以下好处:
- 并行处理:使用消费者组 ID 可以实现多个消费者并行处理同一个主题的消息。每个消费者都可以处理主题的不同分区,从而提高消息处理的并发性能。
- 负载均衡:Kafka 可以确保同一个消费者组中的每个消费者都获得主题中的一部分分区,从而实现负载均衡。这意味着消息处理在消费者组内均匀分布,不会造成某个消费者过载,而其他消费者处于空闲状态。
- 容错性:如果一个消费者失败或离线,Kafka 会将它的分区重新分配给其他在线的消费者,确保消息不会丢失,同时保持负载均衡。这有助于实现高可用性。
- 水平扩展:通过增加消费者,可以轻松地扩展消息处理能力。只需创建更多的消费者并加入同一个消费者组,Kafka 就会自动分配分区,从而实现水平扩展。
如果不使用消费者组 ID,可能会导致以下问题:
- 消息重复处理:每个消费者都会独立地处理同一主题的所有消息,可能导致消息的重复处理。
- 无法实现负载均衡:没有消费者组 ID,无法确保不同消费者之间均匀处理消息,因此某些消费者可能会过载,而其他消费者可能处于空闲状态。
- 无法实现高可用性:没有消费者组 ID,无法轻松实现消费者的容错和高可用性,一旦某个消费者失败,消息处理可能会受到影响。
总之,消费者组 ID 是 Kafka 中实现并行、负载均衡、高可用性和水平扩展的关键机制,因此在使用 Kafka 时通常建议使用消费者组 ID。
# 数据库相关
# 执行插入操作但只有可读权限
背景分析
抛出异常,显示是【只读】的,不允许【修改】
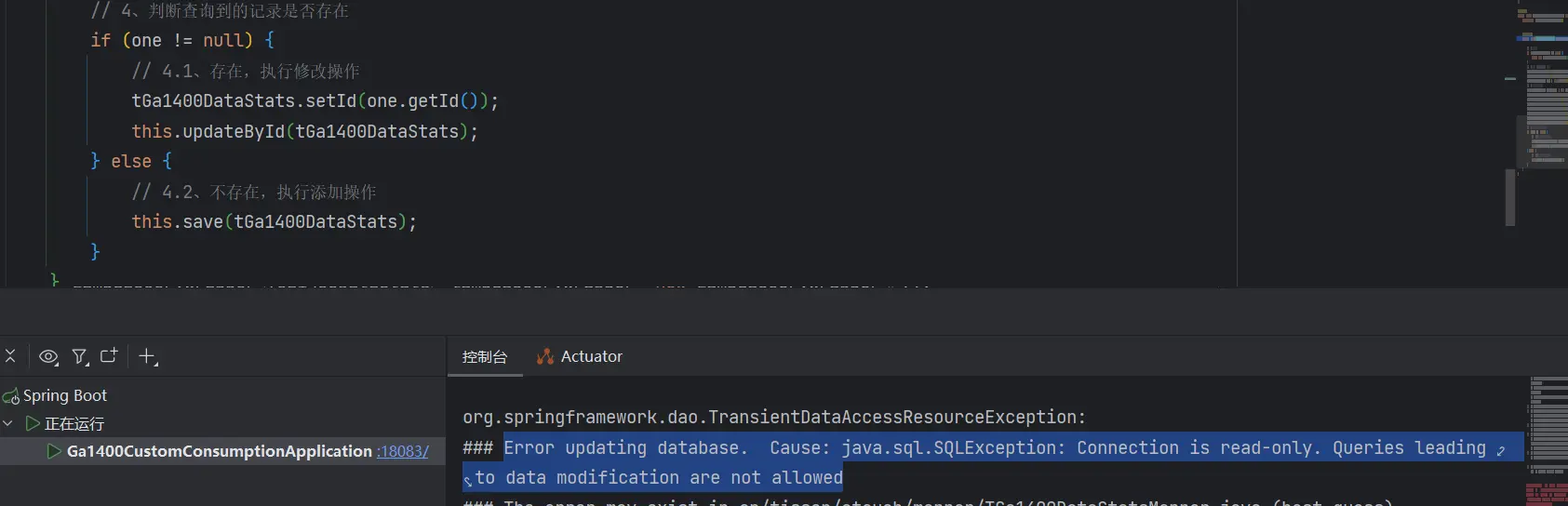
### Error updating database. Cause: java.sql.SQLException: Connection is read-only. Queries leading to data modification are not allowed
### The error may exist in cn/tisson/etouch/mapper/TGa1400DataStatsMapper.java (best guess)
### The error may involve cn.tisson.etouch.mapper.TGa1400DataStatsMapper.insert-Inline
### The error occurred while setting parameters
### SQL: INSERT INTO t_ga1400_data_stats (channel_code, face_received_count) VALUES (?, ?)
### Cause: java.sql.SQLException: Connection is read-only. Queries leading to data modification are not allowed; Connection is read-only. Queries leading to data modification are not allowed; nested exception is java.sql.SQLException: Connection is read-only. Queries leading to data modification are not allowed -------------------
2
3
4
5
6
连接只读。不允许修改数据的查询。
原因(这是项目中定义了【全局事务管理器】的情况)
接口方法命名不规范,在全局事务管理器中被规定为了只读。
部分 全局事务管理器(TransactionManagerConfig) 代码如下:
Map<String, TransactionAttribute> methodMap = new HashMap<>();
//可以提及事务或回滚事务的方法
methodMap.put("add*", requiredTx);
methodMap.put("save*", requiredTx);
methodMap.put("update*", requiredTx);
methodMap.put("modify*", requiredTx);
methodMap.put("edit*", requiredTx);
methodMap.put("insert*", requiredTx);
methodMap.put("delete*", requiredTx);
methodMap.put("remove*", requiredTx);
methodMap.put("repair*", requiredTx);
methodMap.put("bind*", requiredTx);
methodMap.put("binding*", requiredTx);
methodMap.put("batch*", requiredTx);
methodMap.put("clear*", requiredTx);
methodMap.put("append*", requiredTx);
methodMap.put("create*", requiredTx);
methodMap.put("import*", requiredTx);
methodMap.put("change*", requiredTx);
methodMap.put("mod*", requiredTx);
methodMap.put("equ*", requiredTx);
//其他方法无事务,只读
methodMap.put("*", readOnlyTx);
source.setNameMap(methodMap);
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
解决方法
将接口命名修改成 saveXxx 或者 insertXxx 即可,也可在 全局事务管理器 中新加入一种 requiredTx 类型定义
例如:
// 修改前
void countMessageStats(TGa1400DataStats tGa1400DataStats);
// 修改后
void saveCountMessageStats(TGa1400DataStats tGa1400DataStats);
2
3
4
# SQL,聚合函数逻辑错误
背景分析
计算 【当前时间】 和【最新的上传时间】的差,语句报错:"Invalid use of group function"
- 表示在错误的地方使用了聚合函数(例如
MAX)或将聚合函数用于不允许的地方。
错误写法
SELECT
MAX(upload_time) AS lastUploadTime,
DATEDIFF(NOW(), MAX(upload_time)) AS unSentDays
FROM
t_enterprise_market_bills
WHERE
enterprise_id = '1704757410670866434'
AND type = 0
AND DATEDIFF(NOW(), MAX(upload_time)) > 7;
2
3
4
5
6
7
8
9
错误分析
错误原因:
- 聚合函数在
WHERE子句中:MAX(upload_time)是一个聚合函数,它不能直接在WHERE子句中使用。WHERE子句用于过滤行,而HAVING子句用于过滤聚合结果。 - 逻辑顺序错误:
WHERE子句在聚合之前执行,而HAVING子句在聚合之后执行。
正确写法
解决办法:
- 可以使用子查询或使用
HAVING子句来过滤结果。 HAVING子句允许在聚合函数上执行过滤条件。
# 1、使用子查询
SELECT
lastUploadTime,
DATEDIFF(NOW(), lastUploadTime) AS unSentDays
FROM
(SELECT
MAX(upload_time) AS lastUploadTime
FROM
t_enterprise_market_bills
WHERE
enterprise_id = '123321') AS subquery
WHERE
DATEDIFF(NOW(), lastUploadTime) > 7;
# 2、使用 Having 子句
SELECT
MAX(upload_time) AS lastUploadTime,
DATEDIFF(NOW(), MAX(upload_time)) AS unSentDays
FROM
t_enterprise_market_bills
WHERE
enterprise_id = '1704757410670866434'
AND type = 0
GROUP BY
enterprise_id, type
HAVING
DATEDIFF(NOW(), MAX(upload_time)) > 7;
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
# 触发器执行动态 sql 失败
触发器语句
DELIMITER $$
CREATE TRIGGER update_ai_alarm_status
AFTER UPDATE ON t_ai_alarm_stat FOR EACH ROW
BEGIN
IF NEW.status <> OLD.status THEN
SET @today = DATE_FORMAT(NEW.alert_date, '%Y%m%d');
SET @update_status_sql = CONCAT('UPDATE t_ai_alarm_', @today, '
SET status = NEW.status
WHERE alarm_time = NEW.alert_date
AND org_id = NEW.org_id
AND dev_id = NEW.dev_id
AND channel_id = NEW.channel_id
AND alg_type = NEW.alg_type
AND alert_type = NEW.alert_type');
PREPARE create_stmt FROM @update_status_sql;
EXECUTE create_stmt;
DEALLOCATE PREPARE create_stmt;
END IF;
END$$
DELIMITER ;
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
执行报错
1336 - Dynamic SQL is not allowed in stored function or trigger
MySQL不允许在存储函数或触发器中使用动态SQL
2
相关报错:https://blog.csdn.net/weixin_36369848/article/details/113382888 (opens new window)
解决方法
- 尽量少使用触发器,不建议使用。
- 在应用程序上实现该功能,即代码层面
首先创建触发器需要超级用户(Super)的权限
# in 子句查询异常:元素个数太多
背景分析
Excel 表格数据入库功能,对某个字段进行是否存在的校验。
- 表格数据量很大,万级别,并且使用了 in 子句查询
- 因一次性查询的元素个数太多,查询抛出异常
解决方案
# Nacos
# nacos 无法对服务进行上/下线操作
将 nacos 中的 data 目录下的 protocol 文件夹删除,然后重启 nacos 即可
参考:
- 亲测解决,nacos下线失败!_nacos下线无效-CSDN博客 (opens new window)
- Nacos下线节点服务报错caused errCode 500, errMsg do metadata operation failed | 小柒博客 (opens new window)
# 多线程
# 多线程批量插入数据,异常不抛出
背景分析
批量插入 30w 数据,直接使用 Mybatis-Plus 的批量插入,性能过低。
- 因此加入线程池技术,异步批量插入数据
- 运行途中,某个字段的数据过长,超出了表结构的设置的最大长度,导致插入失败
- 某个线程异常了,但是接口运行期间不会抛出异常
- 多线程环境下,没有手动处理事务管理问题
- 默认情况下,Spring 的事务管理器不支持跨线程的事务传播。因此数据没有回滚
总结:
- 多线程环境下(异步方法中),接口遇到异常没有抛出;事务传播失效,数据没有回滚
错误代码
@Override
@Transactional(rollbackFor = Exception.class)
public Boolean importExcel(List<EnterpriseImportExcelVO> importList) {
if (CollUtil.isEmpty(importList)) {
throw exception(ENTERPRISE_IMPORT_LIST_IS_EMPTY);
}
List<EnterpriseDO> doList = BeanUtils.toBean(importList, EnterpriseDO.class);
int batchSize = 1000;
int totalSize = doList.size();
ExecutorService executor = Executors.newFixedThreadPool(Runtime.getRuntime().availableProcessors());
for (int i = 0; i < totalSize; i += batchSize) {
int end = Math.min(i + batchSize, totalSize);
List<EnterpriseDO> batch = doList.subList(i, end);
executor.submit(() -> {
batch.forEach(this::fillEntInfo);
this.saveBatch(batch);
});
}
executor.shutdown();
try {
executor.awaitTermination(Long.MAX_VALUE, TimeUnit.NANOSECONDS);
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
}
return true;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
解决方案
改为手动提交事务
纠正后的代码
@Resource
private DataSourceTransactionManager dataSourceTransactionManager;
@Override
@Transactional(rollbackFor = Exception.class)
public Boolean importExcel(List<EnterpriseImportExcelVO> importList) {
if (CollUtil.isEmpty(importList)) {
throw exception(ENTERPRISE_IMPORT_LIST_IS_EMPTY);
}
List<EnterpriseDO> doList = BeanUtils.toBean(importList, EnterpriseDO.class);
int batchSize = 1000;
int totalSize = doList.size();
final int[] count = {0};
try {
// 使用 CompletableFuture 处理异步任务
List<CompletableFuture<Void>> futures = new ArrayList<>();
for (int i = 0; i < totalSize; i += batchSize) {
int end = Math.min(i + batchSize, totalSize);
List<EnterpriseDO> batch = doList.subList(i, end);
CompletableFuture<Void> future = CompletableFuture.supplyAsync(() -> {
// 手动开启事务
DefaultTransactionDefinition def = new DefaultTransactionDefinition();
// 事物隔离级别,开启新事务,这样会比较安全些。
def.setPropagationBehavior(TransactionDefinition.PROPAGATION_REQUIRES_NEW);
// 获得事务状态
TransactionStatus status = dataSourceTransactionManager.getTransaction(def);
try {
batch.forEach(this::fillEntInfo);
saveBatch(batch);
count[0] += batch.size();
} catch (Exception e) {
// 事务回滚
dataSourceTransactionManager.rollback(status);
throw new RuntimeException(e);
}
return null;
}, marketTaskExecutor);
futures.add(future);
}
// 等待所有任务完成
CompletableFuture.allOf(futures.toArray(new CompletableFuture[0])).join();
} catch (Exception e) {
log.error("[importExcel][导入企业信息异常: {}]", e.getMessage(), e);
throw exception(ENTERPRISE_IMPORT_ERROR);
}
log.info("[importExcel][导入企业信息,数量为({})]", count[0]);
return true;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
# Maven 相关
# 打包时显示找不到符号
背景分析
maven package 或者 install 时打包显示某个类中的代码 找不到符号,导致打包失败。
原因分析
猜测可能是那个 import 引入的类是 sdk 依赖内部的
解决方法
先 install 一下那个 sdk 的 maven 模块
# 下载不到私库的依赖
背景分析
idea 设置中 Maven 主路径的选择:
- IDE 自带的 Maven 版本:
已捆绑(Maven 3) - 本地安装包路径:
D:\software\java\maven\apache-maven-3.9.6
选择第一个,可以下载私库的依赖;选择第二个,下载不了。

原因分析
原因不明...
解决方法
Maven 主路径选择:已捆绑(Maven 3)